-
7:30 - 20:30
Cả CN & Lễ -

-




Hệ sinh thái Hadoop
Hadoop là một trong những công nghệ liên quan chặt chẽ nhất với big data. Dự án Apache Hadoop phát triển phần mềm mã nguồn mở cho máy tính có khả năng mở rộng và phân tán.
Thư viện phần mềm Hadoop là một khuôn mẫu cho phép xử lý phân tán các bộ dữ liệu lớn trên các nhóm máy tính sử dụng các mô hình lập trình đơn giản. Nó được thiết kế để mở rộng từ một máy chủ duy nhất sang hàng ngàn máy khác, mỗi máy cung cấp tính toán và lưu trữ cục bộ.
Dự án bao gồm rất nhiều phần:
Apache Spark
Một phần của hệ sinh thái Hadoop, Apache Spark là một khuôn mẫu tính toán cụm nguồn mở được sử dụng làm công cụ xử lý big data trong Hadoop.
Spark đã trở thành một trong những khuôn mẫu xử lý big data quan trọng, và có thể được triển khai theo nhiều cách khác nhau. Nó cung cấp các phương thức hỗ trợ đối với Java, Scala, Python (đặc biệt là Anaconda Python distro ), và ngôn ngữ lập trình R ( R đặc biệt phù hợp với big data ) và hỗ trợ SQL, streaming data, machine learning và xử lý đồ thị.
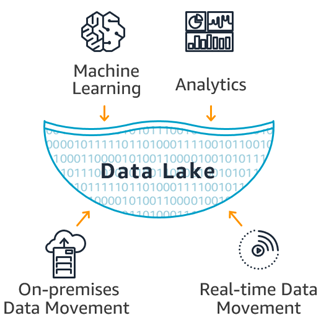
Data lakes
Data lakes là các kho lưu trữ chứa khối lượng dữ liệu thô rất lớn ở định dạng gốc của nó cho đến khi những người dùng doanh nghiệp cần dữ liệu.
Các yếu tố giúp tăng trưởng data lakes là những phong trào kỹ thuật số và sự phát triển của IoT. Các data lakes được thiết kế để giúp người dùng dễ dàng truy cập vào một lượng lớn dữ liệu khi có nhu cầu.

NoSQL Databases
Các cơ sở dữ liệu SQL thông thường được thiết kế cho các transaction đáng tin cậy và các truy vấn ngẫu nhiên.
Nhưng chúng có những hạn chế như giản đồ cứng nhắc làm cho chúng không phù hợp với một số loại ứng dụng. Cơ sở dữ liệu NoSQL nêu ra những hạn chế, và lưu trữ và quản lý dữ liệu theo những cách cho phép tốc độ hoạt động cao và sự linh hoạt tuyệt vời.
Nhiều cơ sở dữ liệu đã được phát triển bởi các công ty để tìm cách tốt hơn để lưu trữ nội dung hoặc xử lý dữ liệu cho các trang web lớn. Không giống như các cơ sở dữ liệu SQL, nhiều cơ sở dữ liệu NoSQL có thể được mở rộng theo chiều ngang trên hàng trăm hoặc hàng ngàn máy chủ.

In-memory databases
Cơ sở dữ liệu trong bộ nhớ (IMDB) là một hệ thống quản lý cơ sở dữ liệu chủ yếu dựa vào bộ nhớ chính (Ram), thay vì HDD, để lưu trữ dữ liệu. Cơ sở dữ liệu trong bộ nhớ nhanh hơn các cơ sở dữ liệu được tối ưu hóa trong đĩa, một điểm quan trọng để sử dụng phân tích big data và tạo ra các kho dữ liệu và các siêu dữ liệu. Đọc thêm Redis là gì?
Các kĩ năng Big data
Big data và các nỗ lực phân tích big data yêu cầu kĩ năng cụ thể, dù là từ bên trong tổ chức hay thông qua các chuyên gia bên ngoài.
Nhiều kĩ năng có liên quan đến các thành phần công nghệ dữ liệu quan trọng như Hadoop, Spark, NoSQL, cơ sở dữ liệu trong bộ nhớ và phần mềm phân tích.
Với độ phổ biến của các dự án phân tích dữ liệu và sự thiếu hụt nhân lực về các kĩ năng trên, việc tìm kiếm các chuyên gia có kinh nghiệm có thể là một trong những thách thức lớn nhất đối với các tổ chức.
TRUNGTAMBAOHANH.COM Sửa Chữa 0 Đồng, Xài Trước Trả Sau